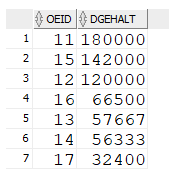
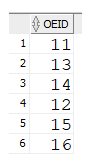Durchschnittsgehalt als Bedingung
SELECT round(avg(gehalt))
FROM mitarbeiter;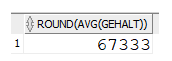
SELECT name
FROM mitarbeiter
WHERE gehalt > 67333
ORDER BY name;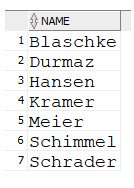
Problem: Manuelle Ermittlung des Durchschnittswertes und Eintragung in die zweite Abfrage
Kombination zweier Aggregierungsstufen:
- Mittelwert aggregiert
- Ausgabe der Namen auf Detailebene
Lösung mit Unterabfrage
Schachtelung von Abfragen
- Übergeordnete Abfrage (Hauptabfrage)
- Unterabfrage
SELECT name
FROM mitarbeiter
WHERE gehalt >= (
SELECT round(avg(gehalt))
FROM mitarbeiter
)
ORDER BY name;Konzeptproblem
SELECT name
FROM mitarbeiter
WHERE gehalt >= (
SELECT round(avg(gehalt))
FROM mitarbeiter
)
ORDER BY name;- Gehalt ist eine Zahl
- Das Ergebnis einer Abfrage ist eine Tabelle
Der Vergleichsoperator
>=
erfordert linke und rechte Seite mit kompatiblen Typ
Ist in diesem Fall gegeben:
Abfrage liefert Ergebnis mit einer Zeile und eine Spalte
Datenzellen
Tabelle

Tabelle, eine Zeile, eine Spalte
Kann als Wert interpretiert werden
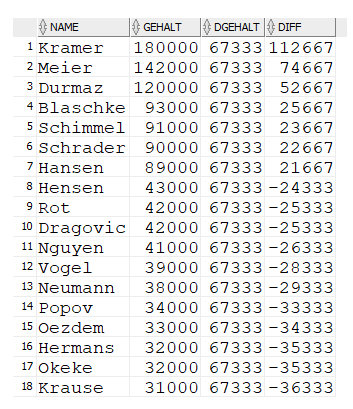
Berechnung mit Detail- und aggregierten Werten
SELECT
name,
gehalt,
(SELECT round(avg(gehalt)) FROM mitarbeiter) AS dgehalt,
gehalt - (SELECT round(avg(gehalt)) FROM mitarbeiter) AS diff
FROM mitarbeiter
ORDER BY
gehalt - (SELECT round(avg(gehalt)) FROM mitarbeiter) desc;Unterabfragen ermöglichen die Kombination von Detail- und aggregierten Werten in einer Abfrage
Common Table Expression (CTE)
Mehrfach verwendete Unterabfragen herausziehen und mit with definieren
with
dg AS (SELECT round(avg(gehalt)) AS dgehalt
FROM mitarbeiter)
SELECT
name,
gehalt,
dgehalt,
gehalt - dgehalt AS diff
FROM mitarbeiter cross join dg
ORDER BY gehalt - dgehalt desc;Jeder Mitarbeiter-Datensatz soll um den Wert "dgehalt" ergänzt werden -> cross join
Unterabfrage mit Werteliste
Alle Mitarbeiter, die in Abteilungen arbeiten, die direkt von Meier (109) geleitet werden
SELECT oeid, name
FROM mitarbeiter
WHERE oeid IN (
SELECT oeid
FROM orgeinheit
WHERE leitung=109
);Unterabfrage liefert:
15
17

Hinter dem Schlüsselwort IN muss eine Liste von Werten kommen
Für eine Unterabfrage bedeutet das: mehrere Zeilen aber nur eine Spalte
Unterabfrage mit Verbund
SELECT oeid, name
FROM mitarbeiter
WHERE oeid IN (
SELECT oe.oeid
FROM orgeinheit oe
join mitarbeiter m ON m.mid=oe.leitung
WHERE name='Meier'
);- Hier dieselbe Abfrage mit Verwendung des Namens 'Meier'
- Erfordert einen Join in der Unterabfrage mit der Mitarbeitertabelle
- Wichtig: Der Join muss über die Leitungsbeziehung erfolgen
Korrelierte Unterabfrage
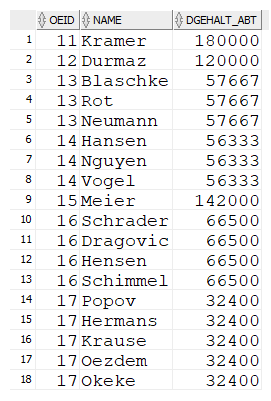
Durchschnitt pro Orgeinheit
SELECT
oeid,
name,
(SELECT round(avg(gehalt))
FROM mitarbeiter dg
WHERE dg.oeid=m.oeid) AS dgehalt_abt
FROM mitarbeiter m
ORDER BY oeid, mid;- Unterschiedliche Werte der Durchschnittsgehälter für Orgeinheiten
- Bezug von der Unterabfrage auf die Hauptabfrage
Unterabfragen im From-Teil
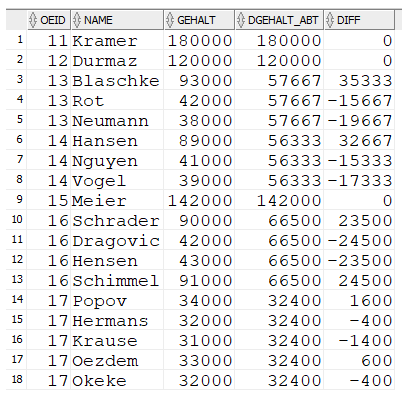
SELECT m.oeid, name, gehalt,
dgehalt_abt,
gehalt - dgehalt_abt AS diff
FROM mitarbeiter m
join
(SELECT oeid, round(avg(gehalt)) AS dgehalt_abt
FROM mitarbeiter
group by oeid) dabt ON m.oeid=dabt.oeid;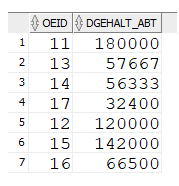
Kann als Ergebnis eine "echte" Tabelle abliefern
Mit CTE
with
dabt AS (
SELECT oeid, round(avg(gehalt)) AS dgehalt_abt
FROM mitarbeiter
group by oeid)
SELECT m.oeid, name, gehalt,
dgehalt_abt,
gehalt - dgehalt_abt AS diff
FROM mitarbeiter m
join dabt ON m.oeid=dabt.oeid;Positionen für Unterabfragen
SELECT |
(SELECT …) - eine Zeile, eine Spalte |
|---|---|
FROM |
(SELECT …) - keine Einschränkungen |
WHERE |
(SELECT …)
|
GROUP BY |
nicht zulässig |
HAVING |
(SELECT …) - eine Zeile, eine Spalte |
ORDER BY |
(SELECT …) - eine Zeile, eine Spalte |
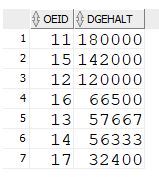
All
Abteilungen mit größtem Durchschnittsgehalt
with
dg AS (
SELECT oeid, avg(gehalt) AS dgehalt
FROM mitarbeiter
group by oeid
)
SELECT oeid
FROM dg
WHERE dgehalt >= all (SELECT dgehalt FROM dg);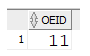
Exists
Abteilungen mit größtem Durchschnittsgehalt
with
dg AS (
SELECT oeid, avg(gehalt) AS dgehalt
FROM mitarbeiter
group by oeid
)
SELECT oeid
FROM dg dg1
WHERE not exists (
SELECT dgehalt
FROM dg dg2
WHERE dg2.dgehalt > dg1.dgehalt
);Some
Abteilungen mit dem nicht-kleinsten Durchschnittsgehältern
with
dg AS (
SELECT oeid, avg(gehalt) AS dgehalt
FROM mitarbeiter
group by oeid
)
SELECT oeid
FROM dg
WHERE dgehalt > some (SELECT dgehalt FROM dg);