Motivation: Konsistenz in verteilten Systemen
Das Problem
- Daten werden auf mehrere Knoten repliziert
- Schreibvorgänge müssen auf alle Replicas übertragen werden
- Netzwerklatenz und Ausfälle verhindern sofortige Synchronisation
- Zwei Clients lesen denselben Schlüssel – und erhalten unterschiedliche Werte
Warum nicht einfach stark konsistent?
- Starke Konsistenz erfordert Koordination aller Replicas
- Koordination kostet Latenz und Verfügbarkeit
- Tradeoff: Konsistenz ↔ Verfügbarkeit ↔ Leistung
Beispiel: Geldabhebung
Node A (EU): Konto = 100 €
Node B (US): Konto = 100 € (Replik)
Client schreibt auf Node A:
Konto = Konto - 50 € → 50 €
Client liest sofort von Node B:
Konto = 100 € ← veralteter Wert!
Frage: Wann ist Node B synchron?
→ Sofort? (starke Konsistenz)
→ Irgendwann? (Eventual Consistency)
→ Nur bei Quorum? (Tunable Consistency)CAP-Theorem / PACELC-Modell
CAP
Drei Garantien – nur zwei gleichzeitig möglich
- C – Consistency: jeder Read liefert den aktuellsten Write oder einen Fehler
- A – Availability: jede Anfrage erhält eine Antwort (kein Fehler, ggf. veraltet)
- P – Partition Tolerance: System funktioniert trotz Netzwerkpartition
Konsequenz
- Netzwerkpartitionen sind in verteilten Systemen unvermeidlich
- → P muss gewählt werden
- → Wahl zwischen C und A bei Partition
- CP-Systeme: Konsistenz bevorzugt
- AP-Systeme: Verfügbarkeit bevorzugt
Netzwerkpartition tritt auf
Node A ──✗── Node B
↑ ↑
Client 1 Client 2
CP: Node B lehnt Reads ab
bis Partition geheilt
→ Fehler, aber konsistent
AP: Node B antwortet mit
möglicherweise veraltetem Wert
→ verfügbar, aber inkonsistentKritik am CAP-Theorem
- Binäres Modell – Praxis ist ein Spektrum
- PACELC-Modell erweitert CAP um Latenz-Tradeoff
PACELC-Modell
- Erweiterung von CAP durch Daniel Abadi (2012)
- Partition → Availability vs. Consistency
- Else (kein Partition) → Latency vs. Consistency
- Auch im Normalbetrieb gibt es einen Tradeoff: schnelle Antwort vs. Koordinationsaufwand
Kategorien
- PA/EL: Verfügbarkeit + niedrige Latenz
- PC/EC: Konsistenz auch im Normalbetrieb
- PA/EC: Verfügbarkeit bei Partition, Konsistenz sonst
BASE
BASE - Basic Available, Soft State, Eventually Consistent
Basic Available
- (Eingeschränkte) Verfügbarkeit als oberstes Ziel
Soft State
- Fenster der Inkonsistenz
Eventually Consistent
- Irgendwann wird ein konsistenter Zustand erreicht
Konsistenzspektrum – Übersicht
Von stark nach schwach (abnehmende Garantien, zunehmende Verfügbarkeit)
| Modell | Garantie | Latenz |
|---|---|---|
| Linearisierbarkeit | Reads sehen zuletzt geschriebenen Wert, global geordnet | hoch |
| Kausale Konsistenz | Kausal abhängige Ops in richtiger Reihenfolge sichtbar | mittel |
| Read your own writes / Monotonic Reads | Ein Client sieht eigene Writes Erneutes Lesen liefert keine älteren Werte |
niedrig |
| Eventual Consistency | Irgendwann konsistent – keine Zeitgarantie | minimal |
Linearisierbarkeit
- Stärkstes Konsistenzmodell für einzelne Operationen
- Jede Operation erscheint atomar und sofort an einem einzigen Zeitpunkt
- Reads sehen stets den aktuellsten abgeschlossenen Write
- Globale, totale Ordnung aller Operationen
- Entspricht dem Verhalten eines einzelnen Servers
Umsetzung
- Konsensprotokoll: Paxos, Raft
- Alle Replicas stimmen vor Rückantwort ab
- Kostet: hohe Latenz, eingeschränkte Verfügbarkeit bei Partition
Beispiel
Zeit →
Client A: Write(x=1) ────────────────▶ OK
Client B: Read(x) ────────▶ 1 ✓
Linearisierbar:
Read nach abgeschlossenem Write
muss neuen Wert liefern
Nicht linearisierbar:
Client A: Write(x=1) ──────────────▶ OK
Client B: Read(x) ──────▶ 0 ✗
(Write abgeschlossen, aber 0 gelesen)Kausale Konsistenz
- Operationen, die kausal voneinander abhängen, werden von allen Prozessen in der richtigen Reihenfolge gesehen
- Kausalität: A → B, wenn B A „gesehen" hat (Happens-Before-Relation)
- Nicht-kausale Ops dürfen in beliebiger Reihenfolge sichtbar werden
- Schwächer als Linearisierbarkeit, besser skalierbar
Happens-Before (→)
- Innerhalb eines Prozesses: alle Ops in Programmreihenfolge
- Nachricht: Senden → Empfangen
- Transitiv: wenn A→B und B→C, dann A→C
Beispiel
P1: Post("Frage?") Write(x=1)
P2: Read(x=1) → Reply("Antwort!")
P3: ?
Kausal konsistent:
P3 sieht erst "Frage?", dann "Antwort!"
(weil Reply kausal von Post abhängt) ✓
Nicht kausal konsistent:
P3 sieht erst "Antwort!", dann "Frage?"
→ Ursache kommt nach Wirkung ✗Veletzung kann bei Sharding auftreten
- Nutzer 1 und 2 schreiben in unterschiedlichen Shards
- Replikate werden entgegen der Schreibreihenfolge aktualisiert
- Shards operieren unabhängig, deshalbe keine globale Ordnung auf den Schreibvorgängen
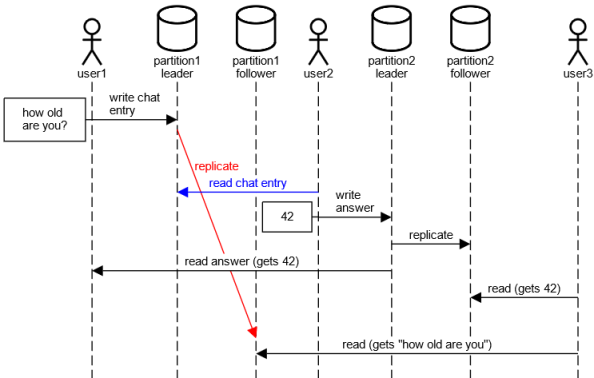
Implementierung: z.B. Vektoruhren
Read your own writes / Monotonic Reads
Read your own writes
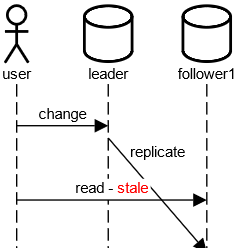
Problem
- Ändern auf dem Leader
- Lesen von einem Follower
- z.B. Lesen von unterschiedlichen Geräten
Lösungsansätze
- Daten, die nur vom Nutzer geändert werden können (z.B. Profil) - Lesen immer vom Leader
- Zeitpunkt der letzten Änderung merken - innerhalb einer Minute immer vom Leader lesen, danach beliebig
- Zeitpunkt der letzten Änderung merken - nur dann von einem Follower lesen, wenn dieser aktueller ist
Monotonic Reads
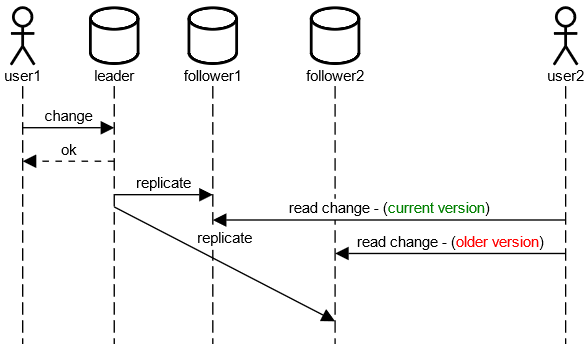
Problem
- Lesen von unterschiedlichen Follower
- Erstes Lesen liefert aktuellere Version als zweites Lesen
Lösungsansatz
- Gleicher Nutzer muss immer vom gleichen Replikat lesen
Eventual Consistency
- Schwächstes praktisch relevantes Konsistenzmodell
- Wenn keine neuen Writes erfolgen, konvergieren irgendwann alle Replicas
- Keine Garantie über Zeitpunkt oder Reihenfolge der Konvergenz
- Leseoperationen können veraltete Werte liefern
Vorteile
- Maximale Verfügbarkeit: kein Warten auf Koordination
- Minimale Latenz: sofortige lokale Antwort
- Geeignet für: Shopping-Carts, DNS, Social Feeds, Sensor-Daten
Herausforderungen
- Anwendung muss mit veralteten Daten umgehen können
- Konfliktauflösung bei konkurrierenden Writes notwendig
Quorum-Konsistenz
- N: Replikationsfaktor (Anzahl Kopien)
- W: Anzahl Bestätigungen beim Schreiben
- R: Anzahl Antworten beim Lesen
Starke Konsistenz: W + R > N
- Lese- und Schreib-Quorum überlappen sich → mindestens eine Replica ist aktuell
- Typisch: N=3, W=2, R=2 → QUORUM
Schwache Konsistenz: W + R ≤ N
- Keine Überlappung garantiert → Reads können veraltet sein
- Typisch: N=3, W=1, R=1 → ONE (Eventual Consistency)
Konfigurationen (N = 3)
| W | R | W+R | Konsistenz |
|---|---|---|---|
| 3 | 1 | 4 > 3 | stark (ALL/ONE) |
| 2 | 2 | 4 > 3 | stark (QUORUM) |
| 1 | 3 | 4 > 3 | stark (ONE/ALL) |
| 1 | 1 | 2 ≤ 3 | eventual |
| 1 | 2 | 3 ≤ 3 | eventual |
Tradeoff
- Hohe W → schreiblastige Systeme langsamer
- Hohe R → leselastige Systeme langsamer
Vektoruhren
- Mechanismus zur Erfassung von Kausalität ohne globale Uhr
- Jeder Knoten hält einen Zähler pro Knoten im System
- Bei Ereignis: eigener Zähler wird inkrementiert
- Bei Nachricht: Vektoren werden komponentenweise per Max gemergt
Vergleich
- V(A) < V(B) → A happened-before B (kausal abhängig)
- V(A) und V(B) unvergleichbar → nebenläufig (Konflikt möglich)
Beispiel (3 Knoten: A, B, C)
Initial: A=[0,0,0] B=[0,0,0] C=[0,0,0]
A schreibt x=1:
A=[1,0,0] → sendet an B
B empfängt, schreibt x=2:
B=max([0,0,0],[1,0,0])+1B
B=[1,1,0] → sendet an C
C empfängt, schreibt x=3:
C=[1,1,1]
Nebenläufig (Konflikt):
A schreibt x=4: A=[2,0,0]
B schreibt x=5: B=[1,2,0]
→ [2,0,0] und [1,2,0] unvergleichbar
→ Konflikt! Auflösung notwendig