Reihung von Beziehungen
Pfadmuster
- Beschreiben eine mehrfache Reihung von Beziehungen
((:Haltestelle)-[:L]->(:Haltestelle)){1,2} - In diesem Fall ein- oder zweimal mal -[:L]->
- Ein Pfadmuster muss von Knoten mit passenden Labels umschlossen werden
- Pfade können einer Variablen zugewiesen werden (p)
liefert eine Liste aller Knoten in einem Pfad undnodes(p)
eine Liste mit den namen alle Knoten (List Comprehnsion)[n IN nodes(p) | n.name]
MATCH p = (
(h1:Haltestelle {name: 'Hohenzollernplatz'})
((:Haltestelle)-[:L]->(:Haltestelle)){1,2}
(hn:Haltestelle)
)
RETURN [n IN nodes(p) | n.name] as pfade;
Pfade beliebiger Länge
Plus-Symbol: Länge größer gleich 1
MATCH p = (
(h1:Haltestelle {name: 'Hohenzollernplatz'})
((:Haltestelle)-[:L]->(:Haltestelle))+
(hn:Haltestelle)
)
WITH p
ORDER BY length(p)
WITH [n IN nodes(p) | n.name] as pfade
RETURN pfade;
Bedingungen über Beziehungen formuliert
Zielhaltestelle darf keine Links mehr haben
NOT EXISTS {(hn)-[:L]->(:Haltestelle)}MATCH p = (
(h1:Haltestelle {name: 'FehrbellinerPlatz'})
((:Haltestelle)-[:L]->(:Haltestelle))+
(hn:Haltestelle WHERE NOT EXISTS {(hn)-[:L]->(:Haltestelle)})
)
WITH p
ORDER BY length(p)
WITH [n IN nodes(p) | n.name] as pfade
RETURN pfade;

Kombination von Pfadmustern
MATCH
(h1:Haltestelle {name: 'Hohenzollernplatz'})
((ha:Haltestelle)-[:L]->(:Haltestelle))+
(hm:Haltestelle)
((hb:Haltestelle)-[:L]->(:Haltestelle))+
(hn:Haltestelle)
RETURN h1.name, [h IN ha | h.name], hm.name, [h IN hb | h.name], hn.name;
Bidirektionale Pfade
MATCH p = (
(h1:Haltestelle {name: 'SpichernStr'})
-[l:L]-*
(h2:Haltestelle {name: 'Wittenbergplatz'})
)
RETURN [n IN nodes(p) | n.name];
Bedingungen in Pfadmustern
MATCH p = (
(h1:Haltestelle {name: 'HeidelbergerPlatz'})
((ha:Haltestelle)-[l:L]->(hb:Haltestelle))*
(h2:Haltestelle {name: 'SpichernStr'})
)
RETURN [n IN nodes(p) | n.name];
MATCH p = (
(h1:Haltestelle {name: 'HeidelbergerPlatz'})
((ha:Haltestelle)-[l:L]-(hb:Haltestelle where hb.name<>'GüntzelStr'))*
(h2:Haltestelle {name: 'SpichernStr'})
)
RETURN [n IN nodes(p) | n.name];
Zugriff auf Beziehungen in Pfaden
MATCH p = (
(h1:Haltestelle {name: 'FehrbellinerPlatz'})
((ha:Haltestelle)-[l:L]->(hb:Haltestelle))*
(h2:Haltestelle {name: 'SpichernStr'})
)
WITH [r IN relationships(p)] as rels
UNWIND rels as r
RETURN startnode(r).name as von, endnode(r).name as bis, r.distanz as distanz;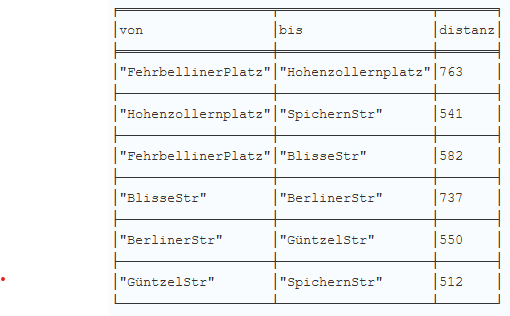
Reduce
MATCH
(h1:Haltestelle {name: 'FehrbellinerPlatz'})
-[l:L]->+
(h2:Haltestelle {name: 'SpichernStr'})
WITH
h1, h2,
[x IN l | startnode(x).name] as hh,
reduce(acc = 0, x IN l | acc + x.distanz) AS distanz
RETURN hh + h2.name, distanz
ORDER BY distanz;
Pfade mit Längeneinschränkung
MATCH
(h1:Haltestelle {name: 'FehrbellinerPlatz'})
-[l:L]->+
(h2:Haltestelle {name: 'SpichernStr'})
WITH
h1, h2,
[x IN l | startnode(x).name] as hh,
reduce(acc = 0, x IN l | acc + x.distanz) AS distanz
WHERE distanz < 2000
RETURN hh + h2.name, distanz
ORDER BY distanz;
Beispiel für eine sehr komplexe Abfrage
MATCH
(stb:Station {name: 'Starbeck'})
<-[:CALLS_AT]-
(a:Stop1 {departs: time('11:11')})
-[n1:NEXT]->*
(b:Stop1)
-[n2:NEXT]->*
(c:Stop1)
-[:CALLS_AT]->
(lds:Station {name: 'Leeds'}),
//
(b:Stop1)
-[:CALLS_AT]->
(l:Station)
<-[:CALLS_AT]-
(m:Stop1)
-[:NEXT]->*
(n:Stop1)
-[:CALLS_AT]->
(lds),
//
(lds)<-[:CALLS_AT]-
(x:Stop1)
-[:NEXT]->*
(y:Stop1)
-[:CALLS_AT]->
(:Station {name: 'Huddersfield'})
WHERE
b.arrives < m.departs AND
n.arrives < x.departs
RETURN
stb.name as start,
b.departs AS harDeparture,
c.arrives AS ldsArrival,
l.name as ChangeAt,
m.departs AS harDeparts,
n.arrives AS leedsArrival,
x.departs AS leedsDeparture,
y.arrives AS arrives
ORDER BY arrives, harDeparts;