Vektordatenbanken
- Speicherung und Verwaltung von Vektordaten
- Effiziente Suche nächstgelegener Nachbarn
- Ähnlichkeitssuche (ANN) statt exakter Gleichheit
- ANN - Approximate Nearest Neighbors
- Semantische Suche
- Distanzmaße
- Index-Strukturen
- Auch in hochdimensionalen Vektorräumen
- Anwendung in Zusammenhang mit
- Semantischen Vektoreinbettungen (Embeddings)
- Großen Sprachmodellen (Large Language Models, LLM)
- Retrieval Augmented Generation (RAG)
Das Grundprinzip

Vektoreinbettungen
- Vektor = Zahlenfeld fester Länge
- Zweidimensional: (3, 5): Vektor der in der Ebene
- Dreidimensional: (3, 5, 1): Vektor im Raum
- 1536-dimensional: (1.7, 2.9, 0.9, ..., 3.4, 4,7): OpenAI-Texteinbettung
- Einbettungen: Umwandlung von Datenobjekten in Vektoren
- Texte, Bilder, Audio, Video
- Erfassung der Bedeutung der Objekte
- Ähnlichkeiten von Wörtern, Bildern usw.
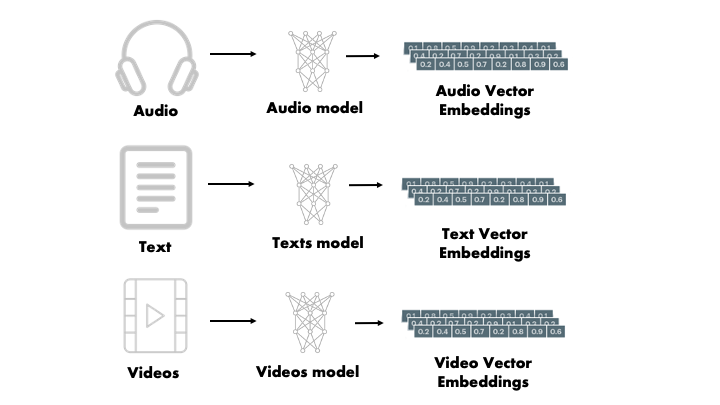
(Quelle)
- Mathematische Repräsentation von Datenobjekten
- Komprimierte, einheitliche Darstellung
- Bewahren Beziehungen in den Daten
- Ergebnis tiefer neuronaler Netze (Deep Learning)
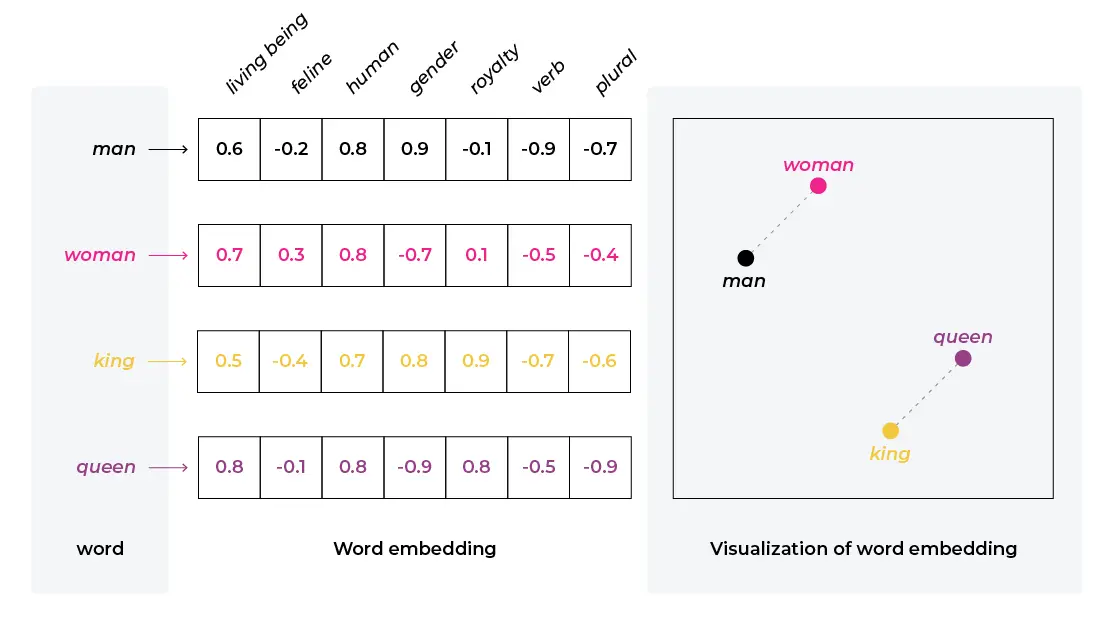
(Quelle)
Was ist ein Embedding?
- Neuronales Netz kodiert Daten als Zahlenvektoren (dense representation)
- Semantisch ähnliche Inhalte → nahe beieinander im Vektorraum
- Dimensionen: 384 (sentence-transformers) bis 3072 (text-embedding-3-large)
- Jede Dimension repräsentiert ein abstraktes Merkmal
Bekannte Modelle
- Text: OpenAI text-embedding-3-*, sentence-transformers, E5, GTE
- Bilder: CLIP, ViT, ResNet-Features
- Code: CodeBERT, StarCoder-Embeddings
- Multimodal: CLIP (Text + Bild in gleichem Raum)

Beispiel Satzeinbettungen
Sentence Transformers

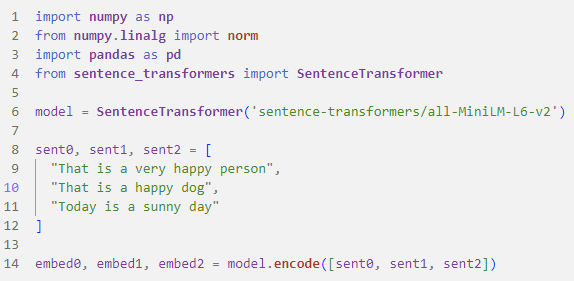
(Quelle)



Explained: Tokens and Embeddings in LLMs (link)
Distanzmetriken
Ähnlichkeiten / Distanzen

Cosinus-Ähnlichkeit
- Misst den Winkel zwischen zwei Vektoren (0° = identisch)
- Unabhängig von der Länge (Magnitude) der Vektoren
- Wertebereich: −1 (entgegengesetzt) bis +1 (identisch)
- Standard für Text-Embeddings
Euklidischer Abstand (L2)
- Gerade Linie im hochdimensionalen Raum
- Sensitiv gegenüber der Vektorgröße
- Geeignet für normalisierte Vektoren und Bildsuche
Dot Product (Skalarprodukt)
- Kombiniert Richtung und Magnitude
- Bei normierten Vektoren identisch mit Cosinus
- Sehr schnell berechenbar (SIMD-optimiert)
Berechnung
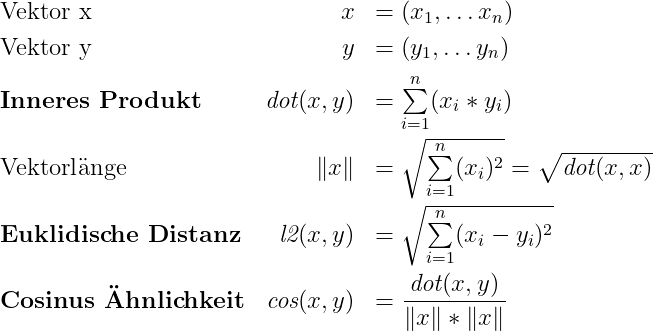
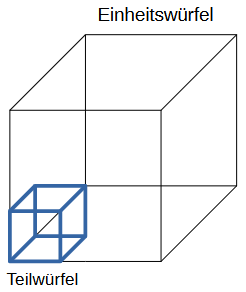
Verteilung im n-dimensionalen Raum
Parameter
- Verteilung von 50 Datenpunkten
- Seitenlänge eines Teilwürfels: 0.2 Einheiten
- Füllgrad der Teilwürfel nimmt drastisch ab
Ein-dimensional

Füllgrad Teilwürfel: 20%
Zwei-dimensional
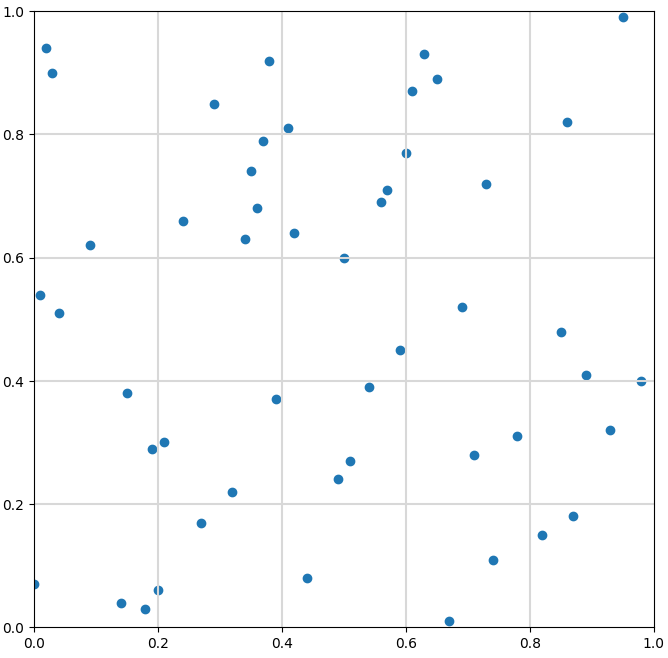
Füllgrad Teilwürfel: 4%
Drei-dimensional

Füllgrad Teilwürfel: 0.8%
Allgemeines Verhalten
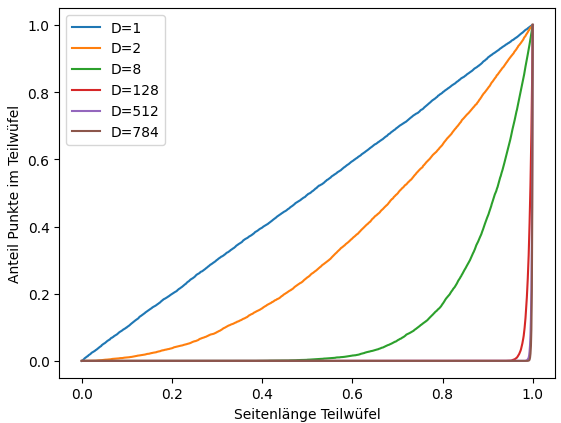
Verhalten der Verteilung bei 20% Seitenlänge
- Ein-dimensional: ca. 20% Datenpunkte
- Zwei-dimensional: ca. 4% Datenpunkte
- Drei-dimensional: ca. 0.8% Datenpunkte
- n>10-dimensional: sehr dünn besiedelter Datenraum
784-dimensional: für 20% der Datenpunkte ist über 99,9% Seitenlänge erforderlich
Distanzen im n-dimensinalen Raum

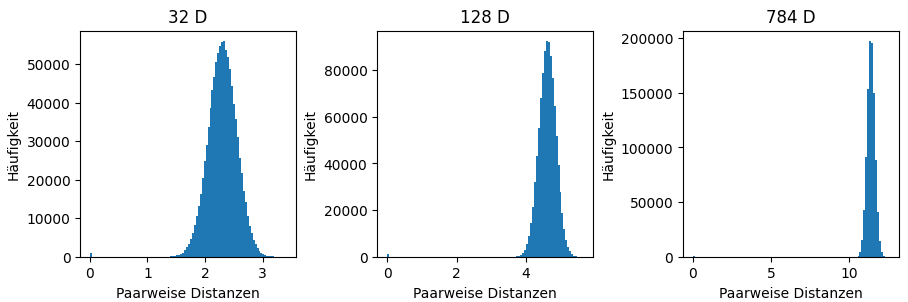
Je mehr Dimensionen, desto
- größer die Abstände
- ähnlicher die Abstände
Fluch der Dimensionalität
Euklidische Distanz verliert an Bedeutung
Suchstrategien in Vektordatenbanken
Exakte Suche (Brute Force)
- Vergleich des Query-Vektors mit allen n Vektoren
- Komplexität: O(n · d) – linear in Datenmenge und Dimension
- Korrekt, aber bei n = 10 Mio. Vektoren zu langsam
- Einsatz: kleine Datenmengen (< 10.000 Vektoren), Prototyping
Approximate Nearest Neighbor (ANN)
- Findet nahezu exakte Nachbarn sehr viel schneller
- Genauigkeit: Recall@10
- Nimm die 10 nächsten approximierten Nachbarn
- Vergleich diese mit den tatsächlich 10 nächsten Nachbarn
- Prozent der approximierten Nachbarn in tatsächlich nächsten Nachbarn
- Ziel: Maximierung des Recall@10
- In RAG
- Minimum brauchbar: 80%
- Gut: 90%
- Sehr gut: 95%
- Index muss einmalig gebaut werden (Preprocessing, Finetuning)
Lineare Suche
Lineare Suche
- Berechne Distanz des Query-Vektors zu allen Vektoren in der DB
- Liefere Vektor mit geringstem Abstand
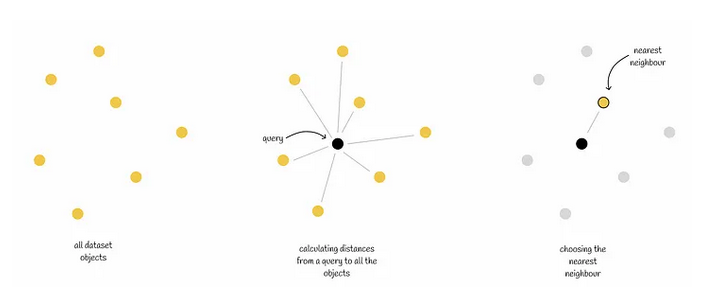
(Quelle)
Inverted File Index
- Partitionierung des Datenraums auf Basis von Clustering, z.B 256 Cluster
- 256 Zentroide
- Berechne Distanz des Query-Vektors zu allen Zentroiden
- Lineare Suche in der Partition des gefundenen Zentroiden
- Liefert Näherungswerte
- Drastische Reduktion der Suchvorgänge
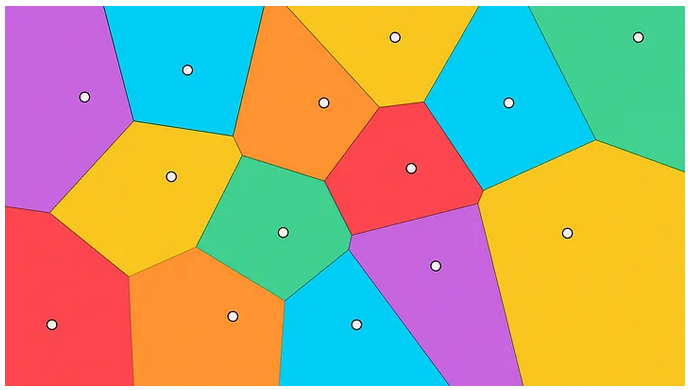
(Quelle)
- Verbesserung der Genauigkeit: mehrere nächste Zentroide, nprobe
- Tradeoff: je größer nprobe, desto genauer aber auch langsamer
- Effizient für sehr große Datenmengen (100 Mio.+ Vektoren)

Skalare Quantitisierung
- Reduzierung der Genauigkeit der Vektoren
- Spart Speicherplatz, z.B. 8-fach bei float64 zu int8
- Schnellere Abstandsberechnungen auf int8 als auf float64
- Mehr Vektoren passen in RAM
- Kleinere Indices
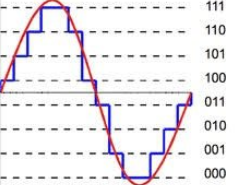
(Quelle)
Produkt-Quantitisierung
- Zerlegung in Subvektoren - Unterräume
- Clustering auf Unterräume
- Kodierung der Subvektoren durch ID des Zentroiden, reproduction value
- Speicherung der Koordinaten der Zentroide
- Kompression
- Originalvektor: 1024 * 32 bits = 4096 bytes
- 8 Subvektoren, 256 Zentroide
- Kodierter Vektor: 8 * 8 bits = 8 bytes
- Faktor 512x Speichersparnis
- Inferenz siehe Quelle
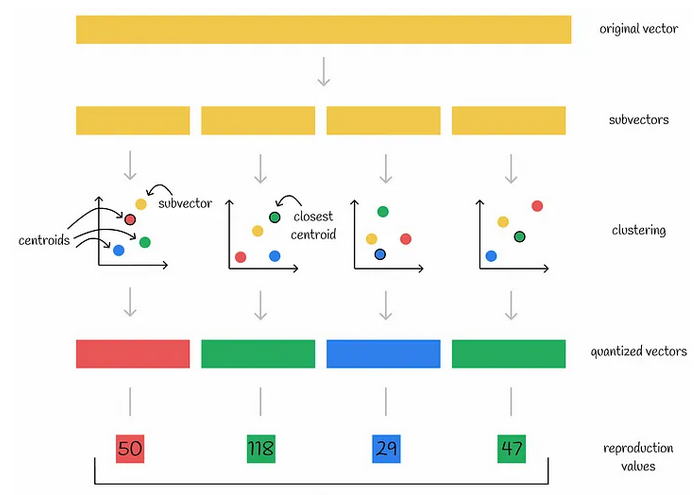
(Quelle)
Hierarchical Navigable Small Worlds (HNSW)
- Umwandlung der Vektoren in einen Graph
- Abstände zwischen Vektoren als Kanten
- Multi-Ebenen-Graph
- Hierarchische Suche im Graphen
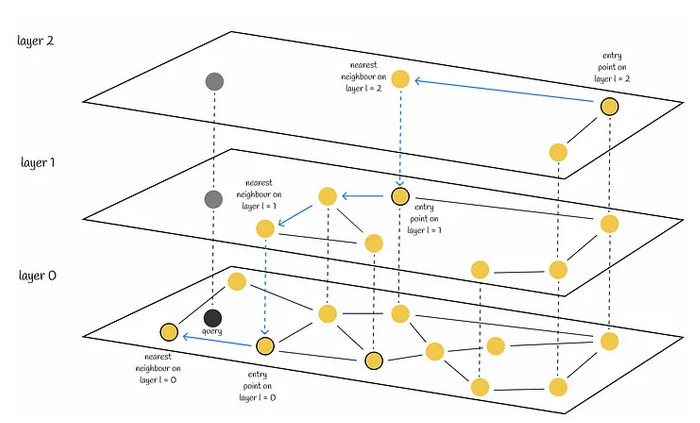
(Quelle)
- Mehrschichtiger Graph: oben grob, unten fein
- Obere Layer: wenige Knoten, Langstreckenverbindungen (Navigation)
- Untere Layer: alle Knoten, dichte lokale Verbindungen (Präzision)
- Suche startet am Entry Point ganz oben und navigiert nach unten
- Suchkomplexität: O(log n)
RAG: Retrieval-Augmented Generation

Hybride Suche
Kombination von Vektorsuche und klassischen Suchalgorithmen wie BM25, wie sie in Suchmaschinen verwendet wird.
BM25 bewertet ein Dokument bzgl. seiner Relevanz für die Suchanfrage
- Wie oft ein Wort in einem Dokument vorkommt
- Wie selten ein Wort in der gesamten Dokumentensammlung vorkommt
- Wie lang das Dokument ist
Favorisiert
- Dokumente die das Wort enthalten
- Dokumente, die das Wort häufiger enthalten, aber mit Kappung, d.h. 10 Auftreten ist nicht 10mal besser
- Dokumente die Worte enthalten, die selten in der Dokumentensammlung vorkommen
Idee
- Vektorsuche allein: brücksichtigt Semantik aber nicht unbedingt Schlüsselwörter
- BM25 Gut bzgl. Schlüsselwörter, kann aber nicht Semantik berücksichtigen
- Hybrid: Kombination beider Verfahren
Kombination der Ergebnisse

- BM25 liefert Ranking A
- Vektorsuche liefert Ranking B
- Beide Rankings werden fusioniert, z.B. mittels Reciprocal Rank Fusion (RRF)
Reciprocal Rank Fusion (RRF)
- Dokumente mit hohem Rang (kleine Zahl) bekommen viel Score
- Dokumente, die in beiden Rankings vorkommen, werden bevorzugt
- Ranglistenfusion: jede Methode liefert eine Rangliste
- RRF(d) = 1/(k + rank-bm25(d)) + 1/(k + rank-vectors(d))
- k = 60 (Typischer Wert), Normalisierungsparameter
- n = Länge der Rangliste, z.B. 100
- rank-bm25(d) = Rang von Dokument d in der BM25-Rangliste oder ∞ falls nicht gefunden
- rank-vectors(d) = Rang von Dokument d in der Vektorsuche-Rangliste oder ∞ falls nicht gefunden
- Rechenbeispiele
Dokument rank-bm25(d) rank-vectors(d) RRF(d) Platz A 1 1 0,032786885 1 B 5 5 0,030769231 2 C 1 10 0,030679157 3 D 1 ∞ 0,016394443 4 E ∞ ∞ 0 5 - Methode robust gegenüber Ausreißer
- Funktioniert gut in praktischen Anwendungen
Anwendungsfälle
- E-Commerce: Produktname (BM25) + Stil (Vektor)
- Code-Suche: Funktionsname (BM25) + Logik (Vektor)
- Rechtliche Suche: Paragraphennummer + semantischer Kontext
Metadaten-Filterung

Warum Filterung?
- Vektoren haben Metadaten: Sprache, Datum, Kategorie, Autor
- Beispiel: "ähnliche Artikel WHERE sprache='de' AND jahr=2024"
Pre-Filtering
- Erst Metadaten filtern, dann ANN auf dem Subset
- Vorteil: präzise, kein Ergebnis außerhalb des Filters
- Nachteil: kleines Subset kann ANN-Qualität reduzieren
Post-Filtering
- Erst ANN (Top-k*), dann Metadaten filtern
- Vorteil: ANN auf vollem Index → hohe Qualität
- Nachteil: evtl. weniger als k Ergebnisse nach Filter
Vektordatenbanksysteme
Pinecone
- Managed Cloud VectorDB (Serverless & Pod-basiert)
- Serverless: automatisches Skalieren, Pay-per-Use
- Namespaces: logische Trennung von Datensätzen
- Metadaten-Filter direkt bei der Suche
- REST API + Python/JS/Java SDK
- Hybrid Search: Dense + Sparse Vektoren (BM25)
from pinecone import Pinecone, ServerlessSpec
pc = Pinecone(api_key="...")
pc.create_index("docs",
dimension=1536,
metric="cosine",
spec=ServerlessSpec(cloud="aws",
region="us-east-1"))
idx = pc.Index("docs")
# Vektoren speichern
idx.upsert(vectors=[
{"id": "v1",
"values": [0.1, 0.7, ...],
"metadata": {"lang": "de"}}])
# Suchen
res = idx.query(
vector=[0.3, 0.5, ...], top_k=5,
filter={"lang": {"$eq": "de"}})Weaviate
- Open-Source, selbst gehostet oder Weaviate Cloud
- Module: eingebaute Vektorisierung (text2vec, img2vec, CLIP)
- Hybrid Search: BM25 + Vektorsuche kombiniert
- GraphQL & REST & gRPC API
- Multi-Tenancy: isolierte Mandanten auf einer Instanz
- Generative Module: direkte LLM-Integration
import weaviate
client = weaviate.connect_to_local()
collection = client.collections.get(
"Article")
# Hybrid-Suche (BM25 + Vektor)
results = collection.query.hybrid(
query="Vektordatenbank Einführung",
alpha=0.75, # 0=BM25, 1=Vektor
limit=5,
return_properties=["title", "content"])
# Vektorsuche mit Filter
results = collection.query.near_text(
query="semantische Suche",
filters=weaviate.classes.query.Filter
.by_property("lang").equal("de"),
limit=5)Chroma
- Leichtgewichtig: eingebettet in Python (SQLite + HNSW)
- Oder als persistenter Server betreibbar
- Ideal für Prototypen, LangChain-/LlamaIndex-Integration
- Automatische Vektorisierung über Embedding-Funktion
- Metadaten-Filter mit
where-Klausel - Kein eigenes Schema erforderlich
import chromadb
client = chromadb.PersistentClient(
path="./vectordb")
col = client.get_or_create_collection(
"docs")
col.add(
documents=["Paris ist die Hauptstadt Frankreichs",
"Berlin ist in Deutschland"],
metadatas=[{"lang": "de"},
{"lang": "de"}],
ids=["doc1", "doc2"])
results = col.query(
query_texts=["Frankreich Hauptstadt"],
n_results=2,
where={"lang": "de"})Qdrant
- In Rust geschrieben – hohe Performance, geringer Speicherverbrauch
- Reichhaltiges Payload-Filtering: Nested-Strukturen, Geo, Volltextsuche
- Quantisierung: Scalar (SQ8), Binary (BQ), Product (PQ)
- On-Disk-Indexierung für sehr große Collections
- GRPC + REST API, Python/JS/Rust/Go SDK
- Cloud-Angebot: Qdrant Cloud
from qdrant_client import QdrantClient
from qdrant_client.models import (
Distance, VectorParams,
PointStruct, Filter, FieldCondition,
MatchValue)
client = QdrantClient(":memory:")
client.create_collection("docs",
vectors_config=VectorParams(
size=768,
distance=Distance.COSINE))
client.upsert("docs", points=[
PointStruct(id=1, vector=[...],
payload={"lang": "de",
"year": 2024})])
results = client.search("docs",
query_vector=[...], limit=5,
query_filter=Filter(must=[
FieldCondition(key="lang",
match=MatchValue(value="de"))
]))pgvector: Vektoren in PostgreSQL
- PostgreSQL-Extension: Vektoren als nativer Spaltentyp
- Volle SQL-Unterstützung: JOINs, Transaktionen, ACID
- Indizes: IVFFlat und HNSW
- Distanzoperatoren:
<=>Cosine,<->L2,<#>Inner Product - pgvectorscale: höhere Skalierung mit DiskANN
- Ideal: bestehende PostgreSQL-Infrastruktur wiederverwenden
-- Extension aktivieren
CREATE EXTENSION vector;
-- Tabelle mit Vektorfeld
CREATE TABLE docs (
id SERIAL PRIMARY KEY,
content TEXT,
embedding vector(1536)
);
-- HNSW-Index (Cosine)
CREATE INDEX ON docs
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
-- Ähnlichkeitssuche Top-5
SELECT content,
embedding <=> '[0.1, 0.7, ...]' AS dist
FROM docs
ORDER BY dist
LIMIT 5;LangChain: VectorStore-Integration
Dokumente indexieren
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
from langchain.text_splitter import (
RecursiveCharacterTextSplitter)
# Dokumente aufteilen
splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(docs)
# Einbetten & in VectorDB speichern
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./db")Suchen & RAG
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
# Ähnlichkeitssuche
results = vectorstore.similarity_search(
"Was ist HNSW?", k=5)
# RAG-Chain aufbauen
from langchain_openai import ChatOpenAI
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="gpt-4o")
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
prompt = ChatPromptTemplate.from_template(
"Beantworte die Frage basierend auf dem Kontext:\n\n{context}\n\nFrage: {input}"
)
qa_chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(retriever, qa_chain)
result = rag_chain.invoke({"input": "Was ist ein Vektorindex?"})
print(result["answer"])