Replikation / Partitionierung
Leader-based Replication
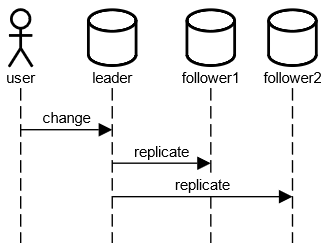
- Verändern der Daten nur über Leader
- Keine Schreibkonflikte
- Leader can Bottleneck werden
- Lesen über alle Knoten
- Follower können veraltete Daten haben
- Leader-Ausfall erkennen
- Leader-Auswahl nach Ausfall
Leaderless Replication
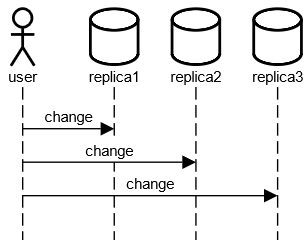
- Verändern der Daten über alle Knoten
- Lesen über alle Knoten
- Replikate können veraltete Daten haben
- Schreibkonflikte möglich
Multi-Leader Replication
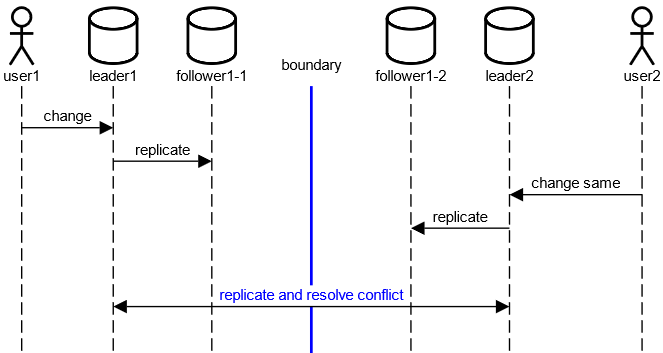
- Ein Leader pro Datacenter
- Vermeidet Latenz über Datacentergrenzen hinweg
- Ansonsten Kombination der Nachteile
Synchrone / Asynchrone Replikation
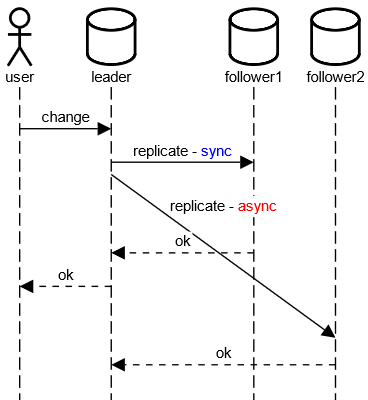
OK an User
- erst nachdem Follower1 bestätigt hat (synchron)
- aber schon bevor Follower2 bestätigt hat (asynchron)
Einrichtung neuer Followers bei leader-based Replikation
- Konsistenter Schnappschuss der Datenbank zum Zeitpunkt t
- Kopieren des Schnappschusses auf den neuen Follower
- Follower verbindet sich mit Leader, um Änderungen zu aktualisieren
Knotenausfälle bei leader-based Replikation
Follower
- Hält auf der lokalen Disk ein Log vor, das die vom Leader erhaltenen Änderungen enthält
- Absturz des Knotens
- Neustart und Wiederherstellung
- Aktualisierung der Änderungen (Rückfrage beim Leader)
- Netzwerkausfall
- Aktualisierung der Änderungen (Rückfrage beim Leader)
Leader
- Feststellung Leader-Ausfall
- Auswahl neuer Leader
- Rekonfiguration System auf neuen Leader
- Mögliche Probleme
- Welcher Timeout für Feststellung Leaderausfall
- Alter Leader wird wieder aktiv, Split Brain - zwei Knoten denken, sie sind Leader
- Neuer Leader ist nicht auf neustem Stand der Daten (bei asynchronen Replikation)
- Alter Leader hat neueren Stand an externe Systeme bereits übertragen
Übertragung Replikationsdaten
Übertragung von Anweisungen
- Nichtdeterministische Funktionen - z.B. now()
- Reihenfolge der Anweisungsausführung
- Seiteneffekte - Trigger, Stored Procedures
Übertragung Transaktionsprotokoll (Write-Ahead-Log, WAL)
- Anwendung des WAL auf dem Follower-Knoten
- Direkte Kopplung an die Speichermaschine
- Kompatibilitätsprobleme bei unterschiedlichen Software-Versionen auf den Knoten
Übertragung von Datensätzen
- Logische Übertragung der Datensatzdaten, nicht physisch wie bei WAL
- Eine Datenbankanweisung kann zu mehreren logischen Datensatzprotokolleinträgen führen
Übertragung auf Anwendungsebene
- Große Flexibilität
- Change Data Capture (CDC)
- Z.B. über Trigger - Eintragung in Protokolltabellen - Auslesen dieser Tabellen
Gossip-Protokoll
- Jeder Knoten kontaktiert zufällig ausgewählte Knoten in der Nähe
- Erhält Rückmeldung, misst Laufzeit bis Antwort kommt
- Meldet an andere Knoten seine gemessenen Werte
- Dadurch verteilte Ermittlung des Gesamtzustands des Systems
- Beinhaltet spezielle Regeln unter welchen Bedingungen ein Knoten als ausgefallen betrachtet wird
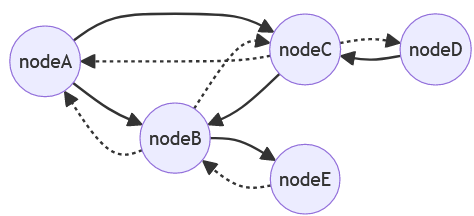
Read Repair
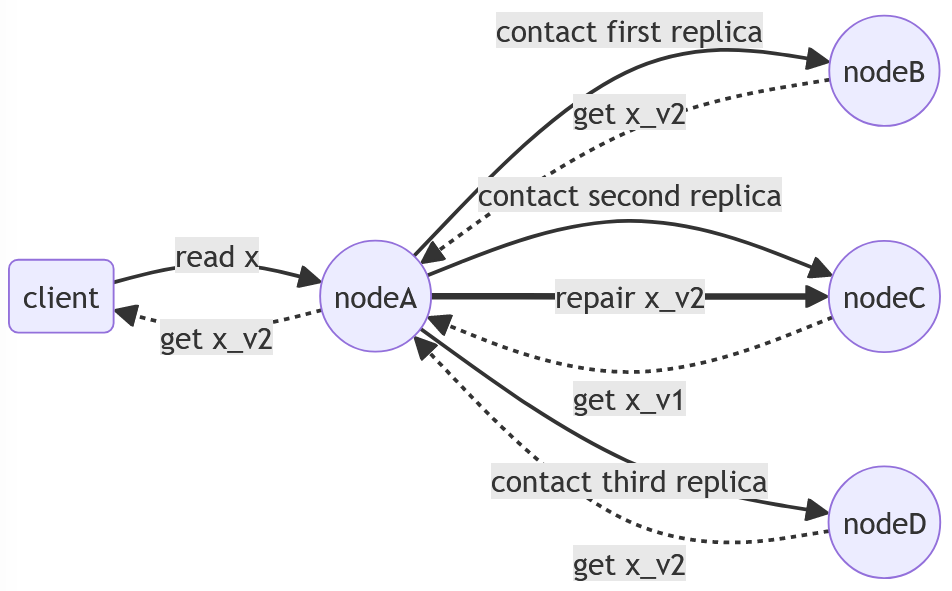
- Hält Replikate auf dem aktuellen Stand
- Im Rahmen von Quorum-Konsistenz
- Problem, wenn ein Wert lange Zeit nicht gelesen wird
Anti-Entropie
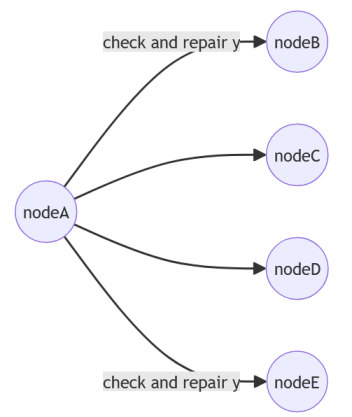
- Hält Replikate auf dem aktuellen Stand
- Läuft periodisch
- Zufallsauswahl
- Ergänzt Read Repair
Partitionierung (Sharding)
- Daten auf verschiedenen Knoten verteilen
- Horizontale Skalierung
- Allokation Daten: z.B. Consistent Hashing
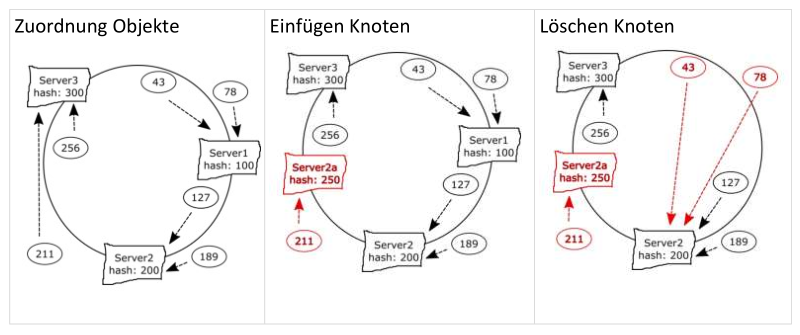
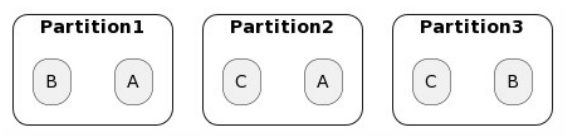
Partitionierung + Replikation
- Datenelemente A, B und C landen in verschiedenen (primären) Partitionen
- Jedes Datenelement wird auf andere Partitionen repliziert
- Replikationsstrategien können konfiguriert werden
- Verschiedene Master für verschiedene Datenelemente möglich
 <
<